
Lately, I’ve been looking into sharing more of the small, technical things we uncover in day-to-day work, especially the kind that don’t make it into case studies or conference talks but still add value.
This is one of those: a micro-optimization in Python that helped us shave precious milliseconds off an AWS Lambda. And like many good discoveries, it started with a question:
—Where are the hidden milliseconds going?
Just like Formula One teams obsess over shaving milliseconds off lap times, we do the same when optimizing serverless execution times. Each request is a lap. If we can make it faster, users feel the difference and so does our AWS bill.
One of our key Lambdas fetches thousands of flight offers from a storage, deserializes them, and applies complex business logic before returning a result. It’s compute intensive, and even small improvements scale dramatically at our volume.
On this journey to improve our “lap time”, I started questioning the Python runtime itself.
Python ≠ C: The Tradeoff
In C, memory allocation is manual, you malloc, you free. You know exactly when memory is claimed and released. In
Python, memory management is automatic. The cyclic garbage collector, usually called just Garbage Collector (GC),
kicks in when thresholds are hit, scanning for unreachable objects.
But here’s the catch, CPython’s garbage collector introduces stop-the-world pauses when
scanning for unreachable reference cycles. This means that all Python code execution halts while the GC
inspects container objects (e.g., lists, dicts, user-defined classes) to detect cycles.
Importantly, reference counting remains active regardless of GC state, disabling GC only defers cycle detection, not memory reclamation for acyclic objects.
This got me thinking:
—What if we simply disabled GC during the Lambda execution?
Unlike persistent server processes, Lambda invocations are ephemeral and isolated. There’s no benefit to collecting garbage cycles during the core compute logic. Most objects are either immediately reclaimed through reference counting or discarded entirely once the function exits. However, because Lambda warm starts may reuse memory between invocations, we explicitly trigger GC at the end to avoid long-term memory buildup.
The Code
import gc
import orjson
def lambda_handler(event, context):
# Disable GC to avoid mid-execution pauses
gc.disable()
try:
# Example: Fetch and process a large payload
raw_offers = store.get("offers") # ~13,000 offers
orjson_loads = orjson.loads
offers = [orjson_loads(raw_offer) for raw_offer in raw_offers]
processed = apply_business_rules(offers)
return format_response(processed)
finally:
# Manually trigger GC after the work is complete
gc.collect()
gc.enable()The Result
Disabling GC during execution led to a significant runtime reduction for this specific Lambda. The in-loop “orjson.loads” step alone dropped from ~1.2s to ~300ms — a 4x improvement in our benchmarks (Figures 1 and 2). While “orjson” itself is implemented in Rust and unlikely to trigger Python GC pauses directly, we observed that downstream processing (e.g., applying business rules on large offer sets) allocates many temporary Python objects. Disabling GC during this phase reduced interruptions from cyclic GC runs.
While the improvement was noticeable, it’s not just a lucky edge case. This optimization is particularly effective in functions that process large in-memory datasets or perform high-throughput transformations using Python-native data structures. In short-lived environments like AWS Lambda, where reference counting handles most memory cleanup and GC pauses can be disproportionately costly, disabling the cyclic GC is a pragmatic performance lever, especially when you control the object lifecycle and explicitly clean up afterward. It’s not about saving memory, it’s about skipping avoidable interruptions.
If that sounds like your use case, consider benchmarking the effect of manually managing the cyclic garbage collector. It’s a subtle trick, and in the right scenario, it scales. Even small performance wins can matter at scale.
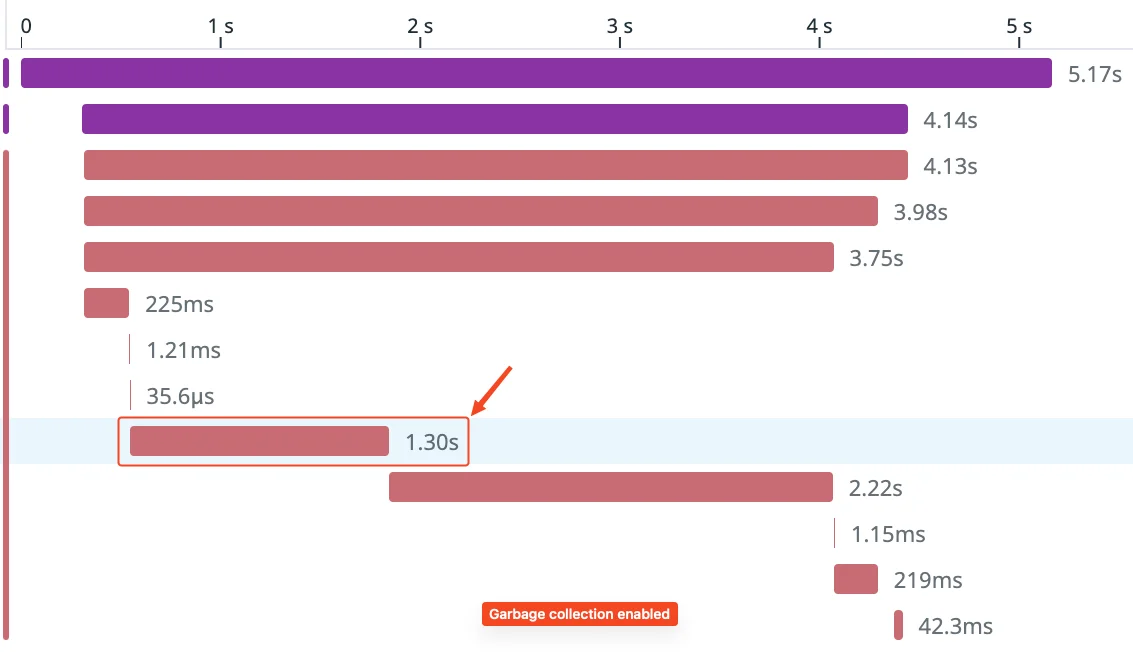
Figure 1. Lambda execution time before disabling the garbage collector. GC introduces pauses during deserialization of large payloads.

Figure 2. Lambda execution time after disabling GC during processing. Execution is significantly faster with GC deferred until the end.
As an extra point, you don’t have to disable GC for the entire handler, either. If you know a particular block of code is responsible for the bulk of allocations (e.g., parsing, transformation), you can scope the optimization more narrowly.
import gc
gc.disable()
run_your_code()
gc.enable()We might not be P1 yet. But we’re definitely in the points.
References
-
CPython Garbage Collector Internals
Explains how Python’s cyclic GC works, including pause behavior and thresholds. -
Operating Lambda: Performance Optimization – Part 1
A deep dive into Lambda internals, cold starts, memory tuning, and other performance levers relevant to production workloads. -
orjson GitHub Repository
High-performance JSON library used in your example, with benchmark comparisons. -
Python
gcModule Documentation
Official reference for disabling GC, triggering manual collection, and inspecting GC stats.